
The More Anthropic Buys Micron HBM, the Faster Optical Memory Pooling Arrives
$MU $MRVL | The Memory Wall and Three Paths Toward Memory Disaggregation




On June 22, 2026, Micron ($MU) announced a strategic agreement with Anthropic bundling a memory supply contract, joint design work, and a strategic investment into Anthropic’s Series H round [1]. Around the announcement, the stock traded at record-high levels [2]. Yet read the full agreement and the words optical, photonic, and interconnect never appear once. HBM, DRAM, SSD. All electrical memory. This piece uses that deal as a doorway to one idea. The memory wall is, at bottom, the problem of feeding data to compute fast enough, and HBM solved it by sitting the memory right next to the GPU. That very adjacency is what blocks the path to more capacity. The moment you pull memory away to add capacity, distance throws you back into the same wall. Carrying bandwidth and latency across that distance is what optics does. There are three paths to memory disaggregation, two of them optical and one electrical. The title is strong on purpose, but the claim in the body is narrower: this deal does not pull optical revenue forward so much as it strengthens the case for why optics becomes necessary. That is the author’s inference, and the body states its limits.
Intro: A Memory Deal With No Optics in It
On June 22, 2026, Micron announced its strategic agreement with Anthropic. Joint memory and storage architecture design, a multi-year supply contract, a strategic investment into Anthropic’s Series H round, and Micron’s internal adoption of Claude, all in one structure [1]. Around the announcement, $MU traded near record highs [2].
Read the agreement from top to bottom and there is no optical, no photonic, no interconnect. HBM, DRAM, SSD. A pure electrical memory deal. You might ask why PhotonCap, which covers optics, would write about this at all.
One thing first. The memory wall is not Anthropic’s problem alone. Any company scaling models, OpenAI or Google or anyone else, stands in front of the same wall. This deal is simply the most recent scene showing how much money that wall now trades for. So this piece uses the Anthropic deal only as a doorway and walks straight into the wall itself.
What the Memory Wall Actually Means
Think of the memory wall as a kitchen. The GPU is a kitchen that takes ingredients (data) and cooks (computes). The trouble is that cooking speed rises every generation, while the speed of bringing ingredients to the stove cannot keep up. However fast the kitchen, if the ingredients arrive late, it sits idle and waits. That waiting is the memory wall. The core issue is not capacity but speed, meaning bandwidth (how much at once) and latency (how quickly it arrives) [3].
HBM’s answer is simple. Put the pantry right next to the stove. Close means fast, and you can move a lot at once. HBM4 is the generation that enlarged this adjacent pantry, doubling the interface width under the JEDEC standard (JESD270-4) to push past 2 TB/s per stack [4]. NVIDIA Rubin secures roughly 22 TB/s with eight such stacks [5].
The catch is that the space next to the stove is small. The edge of the GPU die (the beachfront) has a fixed perimeter, so you cannot attach HBM without limit. Two things follow. First, to add memory you have to add GPUs. Memory and compute get locked into a fixed ratio. Second, there is a ceiling on how much memory a single GPU can reach.
This is where people often misread it. “Can’t you just add capacity? You can always buy more memory.” True. DRAM itself you can always buy more of. But the moment that memory sits far from the GPU rather than beside it, distance drops the bandwidth and stretches the latency. (For how distance and frequency break down an electrical signal, I covered it in detail in DSP, LPO, NPO, CPO: The Four Optical Architectures.) You hit the memory wall again. So the capacity problem is not a wall separate from the memory wall, it is an extension of the same one. The price HBM paid to clear the wall through adjacency is exactly the ceiling on capacity.
DSP, LPO, NPO, CPO: The Four Optical Architectures and the Light Source Beneath Them All

On June 9, an institutional-only SemiAnalysis note lit the fuse, and optics names dropped together. AAOI fell 14%, COHR 11%, LITE 8% [1][2]. The market’s logic was simple: “CPO volume slips to 2028 to 2029, so photonics is over.” Yet the very next day the same names bounced (AAOI +7%, LITE +5%, COHR +2%) [3], and in the same week NTT, SK, and Chunghwa Telecom launched a new $500M fund pointed at optical communications and light sources [4][5]. This piece lays out the four optical architectures, DSP, LPO, NPO, and CPO, in a way a non-specialist can absorb in one read, then maps where Lumentum, Coherent, AAOI, and Sivers actually sit on that ladder. The thesis is one sentence.
The short version: the memory wall is a problem of access speed [3], and HBM solves it by pinning memory right against the GPU. That adjacency creates the fixed ratio and the capacity ceiling, and the moment you try to pull memory away, distance becomes the wall again. To break this loop you have to carry speed across distance. That is where optics enters.
Why It Matters Now: Supply Is Short and Prices Are Rising
That this wall is not abstract is something the memory market is proving right now.
As it happens, Micron reports FQ3 FY2026 results after market close on June 24, 2026. The company’s prior guidance was revenue of $33.5B (plus or minus $750M), gross margin of about 81%, and non-GAAP EPS of $19.15 (plus or minus $0.40) [6]. Consensus just before publication varies by data source (revenue roughly $34B to $35.6B, EPS roughly $19.7 to $20.8), so it is hard to pin to a single number [7]. So rather than the number itself, look at the structure the number points to. If guidance holds, a gross margin near 81% would be the highest in the company’s 47-year history. This is a basis for the bull case and, at the same time, a symptom of the wall. HBM volume for 2026 is already sold out across every supplier [5], and price is the core driver of revenue growth. Prices rise because supply is short. Micron itself has said that as process transitions yield less, more greenfield wafer capacity is needed [8]. That is an admission that adding capacity keeps getting more expensive and slower.
Why this shortage is structural comes down to one ratio. Micron has stated on its earnings calls that, in the same process node, HBM consumes about three times the wafer per bit compared with ordinary DDR5, and that the ratio grows further with HBM4 [9]. Every HBM stack you add takes that much commodity DRAM supply out of the market. That is why the HBM boom drags commodity DRAM prices up with it.
The demand side sends the same signal. In early June, a one-line news item rattled memory stocks for days. The report was that NVIDIA would cut the low-power memory module (SOCAMM2) of its next-generation Vera Rubin server from 192GB to 96GB per module. The Elec and SemiAnalysis pinned the reason on an LPDDR supply shortage [10]. (This sequence is laid out well in Why NVIDIA Halved the Middle Memory. Keep in mind none of it was officially confirmed by the companies. It is reporting.) The market traded this headline twice. First it sold, reading the cut as “AI memory demand has finally cracked,” and a few days later it bought back, reading it as “no, they are rationing because there is not enough to go around.”

Both scenes point to one thing. Memory is short, and the root of the shortage is a structure where usable memory is expensive and that expensive memory has to sit next to compute. If a path opens to add capacity cheaply, decoupled from compute, this pressure eases. That path is memory disaggregation, and that is where optics shows up.
Three Paths Around the Wall: Memory Disaggregation
There is more than one way to pull memory off compute while keeping it usable. (For a map of the optical interconnect layers overall, seen through OFC 2026 papers, see I Read 24 Papers.) It splits into three paths, two of them optical and one electrical.
Path 1. Optical I/O chiplet (optical, the foundation). This is the path of building the optical input and output itself that holds bandwidth and latency when memory travels over distance. Ayar Labs is the representative. It drops an optical I/O chiplet called TeraPHY into the GPU or accelerator package, converting the electrical signal to light at the package edge and sending it out. It runs at roughly 8 Tbps bidirectional with latency around 10 to 25 nanoseconds, and because it extends the UCIe standard into optics, it is not locked to any single chip [11][12]. This is not a memory product but the foundation layer that lets memory sit far away. Ayar, with NVIDIA and AMD as investors, raised a $500M round in March 2026 and remains an independent company [11]. (For why CPO entered scale-out before scale-up, I covered it in Taiwan GTC Computex 2026: CPO.)
Taiwan GTC (Computex 2026): CPO Just Entered Production, So Why Are Coherent and Lumentum, the Companies It Was Supposed to Kill, Still on the Supplier List?

On May 31, 2026 (US press release date, Taiwan GTC Taipei keynote), NVIDIA called Spectrum-X Ethernet Photonics “now in production.” It is the world’s first co-packaged optics (CPO) Ethernet switch built on 200G SerDes, with CoreWeave, Lambda, and Oracle Cloud Infrastructure among the first adopters. One caveat up front: “now in production” marks the start of a manufacturing ramp, while broad availability is guided to the second half of 2026, so the two should be read separately. CPO pulls optical I/O right next to the switch silicon, so the market’s first reaction was pluggable transceiver cannibalization. Yet on the 11-partner supply chain list NVIDIA disclosed back in 2025, the very companies that build pluggables (Coherent, Lumentum) show up again as CPO suppliers. This piece looks at who actually builds what behind that one-line “production” claim, and how cannibalization and upside can happen inside the same company at once.
Path 2. Optical memory fabric, O-HBM (optical, a complement to HBM). This specializes optical I/O for memory, bringing HBM not beside the GPU but optically to any point on top of the die. Celestial AI’s Photonic Fabric is the representative. (For the technology itself and the denominator behind the “25x” claim, I laid it out in NVIDIA’s $2B Marvell Bet and Celestial AI’s “25x” Claim.) The core is letting the processor address, on top of the die-edge electrical HBM, optically connected HBM (O-HBM) as well [13]. One important positioning point.

This does not replace electrical HBM, it adds on beside it as a complement. You can free up the die edge to attach more electrical HBM there, or hang additional HBM optically. (For the structure of freeing the die edge to load more HBM, I covered it in detail in Copper Wall, Age of Light.) It pushes the capacity ceiling itself upward.
Copper Wall, Age of Light — Dissecting Marvell's FY2026 & the 1.6T Optics Chain

Every time AI semiconductors come up, it’s always the same three names: Nvidia, AMD, Broadcom. Important companies, sure. But I think the real money is increasingly moving elsewhere.
Path 3. CXL DRAM pooling (an electrical bypass, a candidate for later optical extension). Instead of buying more expensive HBM and GPUs to add capacity, this binds cheap commodity DRAM (DDR5) into a shared pool that multiple accelerators draw from. It is a slower tier than HBM, so it cannot stand in for HBM, but it substitutes for the cost of “buying more compute just to get capacity.” Strictly speaking, though, this path is not optics itself. XConn, which Marvell acquired, currently ships PCIe and CXL switching silicon (PCIe 5 / CXL 2.0 in production, PCIe 6 / CXL 3.1 sampling), and its role is near-range memory disaggregation [14]. Once the pooling radius reaches beyond the rack, the distance and power limits of electrical CXL can be complemented by optical I/O. So it is electrical for now, with optics as the next extension candidate.
In one line: Path 1 lays the road, Path 2 grows HBM along that road, and Path 3 routes around having to buy more HBM at all. (For how to cut the memory cost itself, How the Memory Tax Gets Solved takes a different angle on it well.)

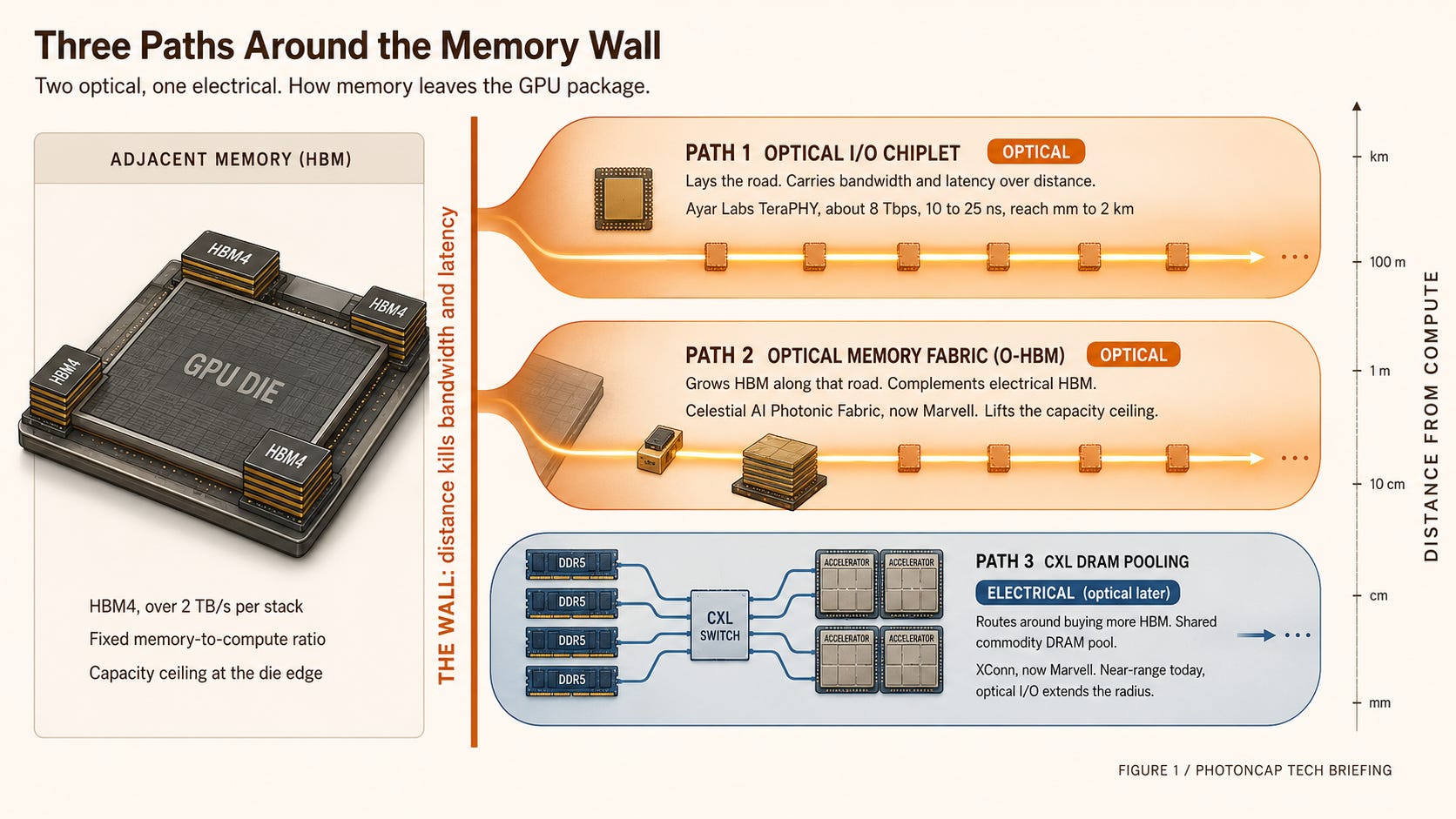
Figure 1: The three paths to memory disaggregation. Path 1 optical I/O chiplet (optical, foundation) / Path 2 O-HBM (optical, HBM complement) / Path 3 CXL DRAM pooling (electrical bypass, optical as later extension). Show each path’s role, representative company, distance/latency zone, and whether it is optical
Who, and When: Supply Chain and Investment Points
The three paths differ by company and by timing. This is where it splits from an investment view.
Independent vs consolidated. Path 1’s Ayar stays an independent company with NVIDIA and AMD as investors, tied into Taiwanese ASIC partners like Alchip and GUC and into TSMC packaging [11]. Paths 2 and 3, by contrast, Marvell gathered under one roof. It announced Celestial in December 2025 and closed it on February 2, 2026 ($3.25B base, up to $5.5B with milestones) [15][16], and it completed the XConn acquisition on February 10, 2026 [14]. (For the quarter where these two acquisitions first showed up in the numbers, I covered it in The Third Signal in May: Marvell Confirms.) So the optical memory fabric and CXL pooling consolidated into $MRVL, while the optical I/O chiplet layer remains in the independent camp (Ayar and others).
The Third Signal in May: Marvell Confirms the AI Optical Signal from Lumentum and Coherent

Over a single month in May, the same demand signal emerged from three layers of the AI optical supply chain. Laser source (Lumentum, 5/5), transceiver/CPO (Coherent, 5/6), DSP/switch/SiPh (Marvell, 5/27). All three companies raised their forward demand visibility for AI optical interconnects, and all three secured $2B strategic commitments from the same counterparty: NVIDIA. Marvell posted Q1 FY27 revenue of $2.418B (+28% YoY), raised its interconnect growth outlook from +50% to +70%, and lifted FY28 revenue guidance to $16.5B, a $1.5B increase. This article analyzes the Marvell earnings while mapping why all three earnings paint the same picture, and where each company and layer sits within that picture.
The layer underneath. Optical Paths 1 and 2 both need a light source (laser) to make the light and a foundry to print the PIC. Path 3’s CXL pooling is electrical for now, but as the pooling radius grows, an extension layer that meets optical I/O appears. Ayar’s SuperNova light source uses Sivers’ DFB laser, and TeraPHY runs on GlobalFoundries and TSMC processes [12]. This light-source, foundry, and packaging layer is the common ground that gets laid no matter which way the optical paths go. (For NVIDIA’s bets on this light-source and optical layer, see Coherent, Lumentum, Marvell, and Now Corning.)
Coherent, Lumentum, Marvell, and Now Corning: NVIDIA’s 4 Photonics Bets and the Path of Light

NVIDIA made four direct investments into photonics companies in 2026. Coherent and Lumentum got $2B each on March 2, Marvell got $2B on March 31, and on May 6 Corning got a $500M warrant deal plus a multi-year commercial partnership. The first three sit in the transceiver, laser, and DSP layers, the companies that generate, control, and interface with light. The fourth one, Corning, makes the medium that light actually travels through: optical fiber, cable, and connectors. This article walks through why NVIDIA’s fourth bet went to a different layer, and why the connectivity layer matters as much as the transceiver layer.
Timing. This matters most. Marvell has guided that meaningful revenue from Celestial begins in the second half of FY2028, reaching a $500M annualized run rate in Q4 FY2028 and $1B in Q4 FY2029 [16]. XConn is earlier, with revenue beginning in Q3 FY2027, a $50M annualized run rate in Q4 FY2027, and $100M in FY2028 [14]. Both paths have a gap before revenue ramps in earnest, and optical O-HBM runs a step behind electrical CXL. Ayar likewise puts the real maturing of the optical I/O market at 2026 to 2028 [11].
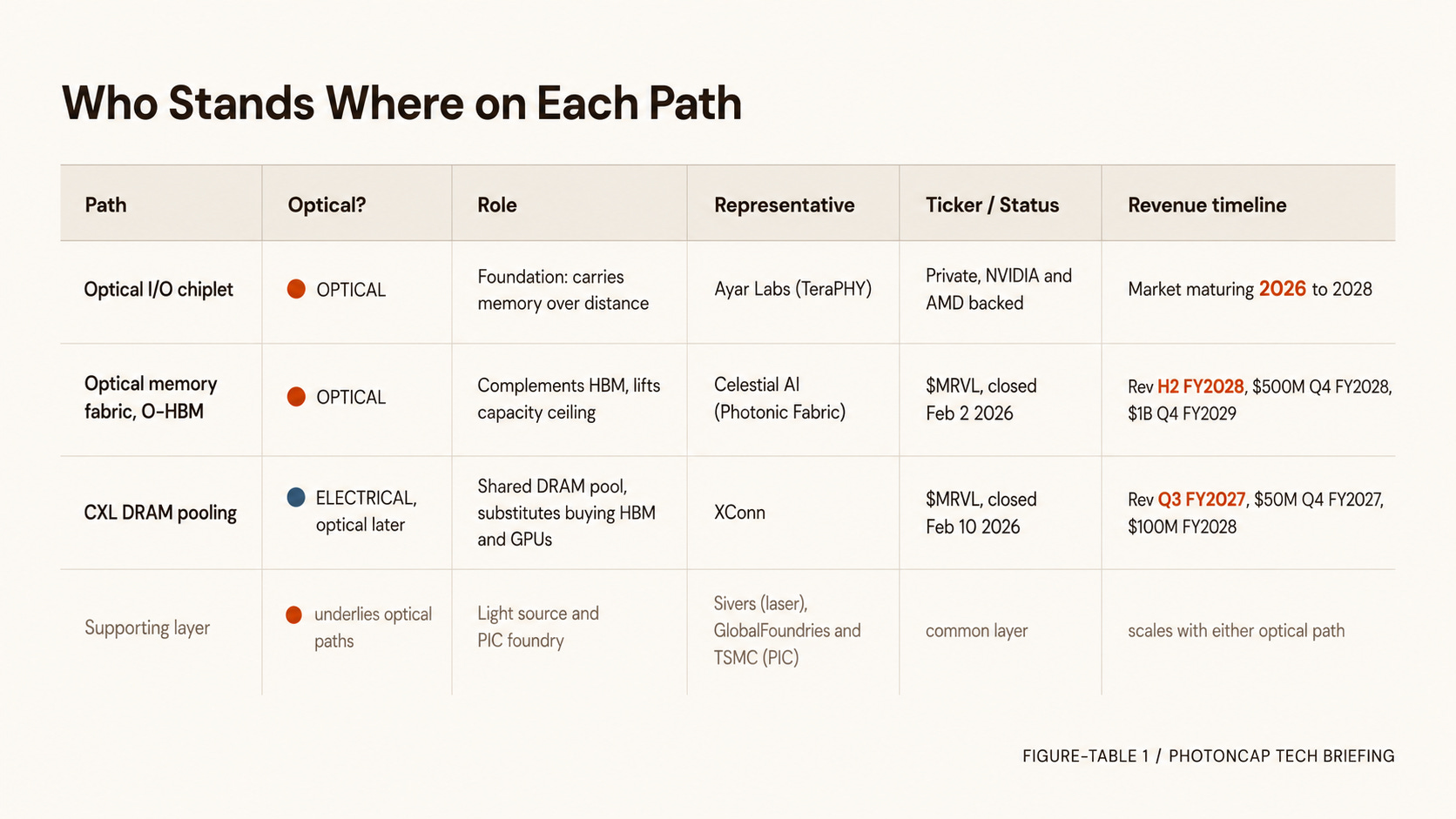
Figure-Table 1: Supply-chain positioning of the three memory-disaggregation paths. Path / Optical? / Role / Representative / Ticker or Status / Revenue Timeline
Net of it, the path to unlocking capacity is not waiting on invention. A company stands on each path, Paths 2 and 3 gathered into $MRVL, and Path 1 left in the independent camp. The remaining variables are adoption speed and the different revenue timelines per path. Electrical CXL first, optics next.
How This Deal Moves the Clock (Author’s Inference)
From here on this is not what a primary source states directly but the author’s inference. Let me be clear about that going in.
The Micron-Anthropic deal locks in electrical HBM on a multi-year basis [1]. In the short run this is not favorable to optical disaggregation. If anything, it fixes electrical HBM demand in place. So the frame that “optics rode along on this deal” is wrong.
But from the capacity angle, the direction flips. A commitment to scale frontier models on a multi-year basis means hitting the constraint that memory must sit next to compute more often and harder. No matter how high you push HBM bandwidth, as long as capacity cannot be separated from compute, a workload that needs more capacity has to buy more GPUs alongside, and that pushes total memory prices higher through the structure where HBM eats about three times the wafer of DDR5 [9]. The stronger the electrical HBM lock-in, the greater the pressure to separate and add capacity cheaply, meaning the case for memory disaggregation grows.
The limits of this inference are clear. First, this is not a conclusion Micron or Anthropic stated, but the author’s inference drawn from the structure of the memory wall. Second, a stronger case does not automatically speed up adoption. There are separate gates of yield, latency validation, and customer qualification. Third, timing is the crux. The pressure builds now, but optical revenue is FY2028 and beyond, so this is a lag play, not a catalyst. The “clock” in the title is the hook, and the more precise word is “the case.”
Scenarios
Labels are qualitative only. No probability percentages.
Base Case. Electrical HBM stays the center of data center memory through 2026 and 2027. Multi-year deals like Micron-Anthropic keep coming, adjacent memory bandwidth keeps strengthening [4], and the sold-out posture holds [5]. Memory disaggregation begins showing up in revenue with electrical CXL (XConn) from FY2027 and optics (Celestial) from FY2028 [14][16], building share gradually as a lag play.
Alternative. Capacity pressure surfaces faster than expected. Of the three, CXL pooling (Path 3) gets adopted before optical O-HBM, at near range, serving as the first bypass [14]. In this case the optical I/O chiplet (Path 1) and O-HBM (Path 2) follow as the next step.
Downside. Capacity gets routed around without disaggregation. Per-stack capacity gains in HBM4E (48GB 12-high and the like) and model-side memory efficiency (quantization, offloading) delay the pain enough that the case for optics weakens and the revenue timeline slips further out [17].
What to Monitor
The June 24 Micron earnings call: 2027 HBM visibility, ASP and price durability, margin hold, greenfield capacity comments, and the actual beat against a consensus that varies by source [6][7][8]. The stronger the shortage and pricing power, the more the capacity pressure shows up in the numbers.
The quarter where Celestial and XConn figures get broken out in Marvell’s results. Whether the FY2027 (XConn) and FY2028 (Celestial) guides pull forward or slip is the speedometer [14][16].
Customer qualification, tape-out, and volume announcements from the independent optical I/O camp like Ayar. Whether Path 1 moves first [11].
Official adoption of memory pooling and disaggregation by hyperscalers. Whether the electrical CXL path (Path 3) or the optical path (Paths 1, 2) comes first.
HBM4E capacity density, the DRAM price curve, and module configuration shifts like SOCAMM [10][17].
PhotonCap’s View
This deal has no optics in it. That is a fact, and the right move is to accept it as is. The frame that optics rode directly onto a memory deal is overclaim.
Here is the picture I see instead. The memory wall is a problem of access speed, and HBM solved it through adjacency while creating a capacity ceiling. Pushing that ceiling across distance is memory disaggregation, and it has three paths: optical I/O chiplet (optical), O-HBM (optical) [13], and CXL pooling (electrical, with optics as a later extension). Paths 2 and 3 are already gathered into $MRVL [15], and Path 1 remains in the independent camp. The order is electrical CXL first into revenue, optics following. This deal does not pull that clock forward directly, but it hardens the case for pulling memory off compute. My positions ($POET, $LWLG) do not map cleanly onto this memory-pooling set, so I have left them out of this article’s analysis.
Coming Next
This piece goes as far as the “necessity” of disaggregation. Why it is needed, who stands where. The next paid piece will go a step deeper into when optical memory actually becomes revenue, through which yield and validation gates, and the realistic roadmap per path. Necessity and feasibility are different convictions.
References & Sources
[1] Micron Technology, “Micron and Anthropic Announce Strategic Agreement to Scale Next-Generation AI Infrastructure”, 2026.6.22. Joint memory/storage design, multi-year supply contract, Series H investment, internal Claude adoption.
[2] TheStreet, “Bank of America strongly resets Micron stock price target”, 2026.6. $MU trading at record-high levels around the Anthropic deal, 800%+ one-year return.
[3] Introl, “The AI Memory Supercycle”, 2026.1. Memory wall definition. Bandwidth and latency of feeding data to compute as the bottleneck.
[4] Siemens, “HBM3e and HBM4: IC design guide for next-generation high bandwidth memory”, 2026.4. JEDEC JESD270-4 (2025.4), 2048-bit, 32 channels, over 2 TB/s per stack, up to 64GB/stack.
[5] Introl, “South Korea’s HBM4 Moment”, 2026.1. Rubin 288GB HBM4 across 8 stacks, about 22 TB/s. SK Hynix, Micron 2026 HBM volume sold-out guidance.
[6] Micron Technology, “FQ2 2026 Results and FQ3 Guidance” (SEC Form 8-K, Ex-99.1), 2026.3. FQ3 guide revenue $33.5B (plus or minus $750M), gross margin about 81%, non-GAAP EPS $19.15 (plus or minus $0.40).
[7] indmoney, “Micron Earnings Preview: HBM, AI Memory Demand & MU Stock Outlook”, 2026.6. June 24 report, consensus varies by source, revenue roughly $34B to $35.6B, EPS roughly $19.7 to $20.8. (Consensus estimate, varies by source.)
[8] Micron Technology (investor conference comments), “Micron IR Earnings Summary & Outlook (J.P. Morgan TMT Conference)”, 2026.5. Demand exceeding supply, tightness persisting beyond 2026, price as the core driver of revenue growth, lower process-transition productivity requiring greenfield wafer capacity.
[9] Tom’s Hardware (citing Micron management), “HBM is coming for your PC’s RAM”, 2025.12. Per Micron’s earnings remarks, HBM consumes about three times the wafer of DDR5 per bit at the same node, with the ratio widening for HBM4. (Micron CEO Mehrotra, FQ2/Q3 FY2024 call.)
[10] The Elec, “Nvidia Cuts SOCAMM2 Capacity in Half Amid LPDDR Shortage”, 2026.6.9. SOCAMM2 module cut from 192GB to 96GB, attributed to LPDDR shortage (originating from SemiAnalysis reporting, June 4). Not officially confirmed by the companies.
[11] DatacenterDynamics, “Optical interconnect startup Ayar Labs closes $500m funding round backed by Nvidia and AMD”, 2026.5. NVIDIA/AMD-backed $500M round (2026.3), TeraPHY optical I/O, Alchip/TSMC partners, independent.
[12] Gazettabyte, “Ayar Labs prepares to fulfil its optical input-output (I/O) vision”, 2026.2. TeraPHY 8 Tbps bidirectional, UCIe extended into optics, SuperNova using Sivers DFB laser, GlobalFoundries/TSMC processes.
[13] Optics.org, “Celestial AI lands $100M for optical interconnects”, 2023. OMIB, O-HBM, optical delivery to any point on the die. (Includes Celestial’s own claims.)
[14] Marvell Technology, “Marvell Completes Acquisition of XConn Technologies”, 2026.2.10. PCIe and CXL switching silicon. PCIe 5/CXL 2.0 production, PCIe 6/CXL 3.1 sampling. Revenue beginning Q3 FY2027, $50M annualized run rate Q4 FY2027, $100M FY2028.
[15] Marvell Technology, “Marvell Completes Acquisition of Celestial AI” (SEC Form 8-K/A, Ex-99.1), 2026.2.2. Acquisition closed.
[16] Marvell Technology, “Marvell to Acquire Celestial AI, Accelerating Scale-up Connectivity”, 2025.12.2. $3.25B base up to $5.5B, pooled memory appliances noted, revenue beginning 2H FY2028, $500M Q4 FY2028, $1B Q4 FY2029.
[17] TechTimes (reporting), “SK hynix Ships 12-Layer HBM4E Samples Ahead of Schedule”, 2026.6.19. 48GB 12-high HBM4E samples.
Disclaimer: This article is an independent, engineering-driven technical analysis published by PhotonCap. All content is based on publicly available information and is intended for educational and informational purposes only. Nothing herein constitutes a recommendation to buy, sell, or hold any security. The author may hold positions in securities discussed and may transact at any time without notice. Readers should conduct their own due diligence before making any investment decisions.

