
Copper Wall, Age of Light — Dissecting Marvell's FY2026 & the 1.6T Optics Chain


Every time AI semiconductors come up, it’s always the same three names: Nvidia, AMD, Broadcom. Important companies, sure. But I think the real money is increasingly moving elsewhere.
On March 5, 2026, Marvell Technology (MRVL) released its FY2026 Q4 results, and it only reinforced my conviction: the real bottleneck in AI infrastructure is no longer the GPU — it’s the pipeline that moves the data. And at the heart of that pipeline is optics.
This isn’t just a quarterly earnings surprise. I see it as a landmark that stamped the arrival of the second wave of the AI hardware supercycle onto global capital markets.
Today I’m anchoring on Marvell’s earnings to take apart the entire optical interconnect value chain — from deep tech analysis to competitive dynamics, TAM estimates, geopolitical risks, and investment strategy.
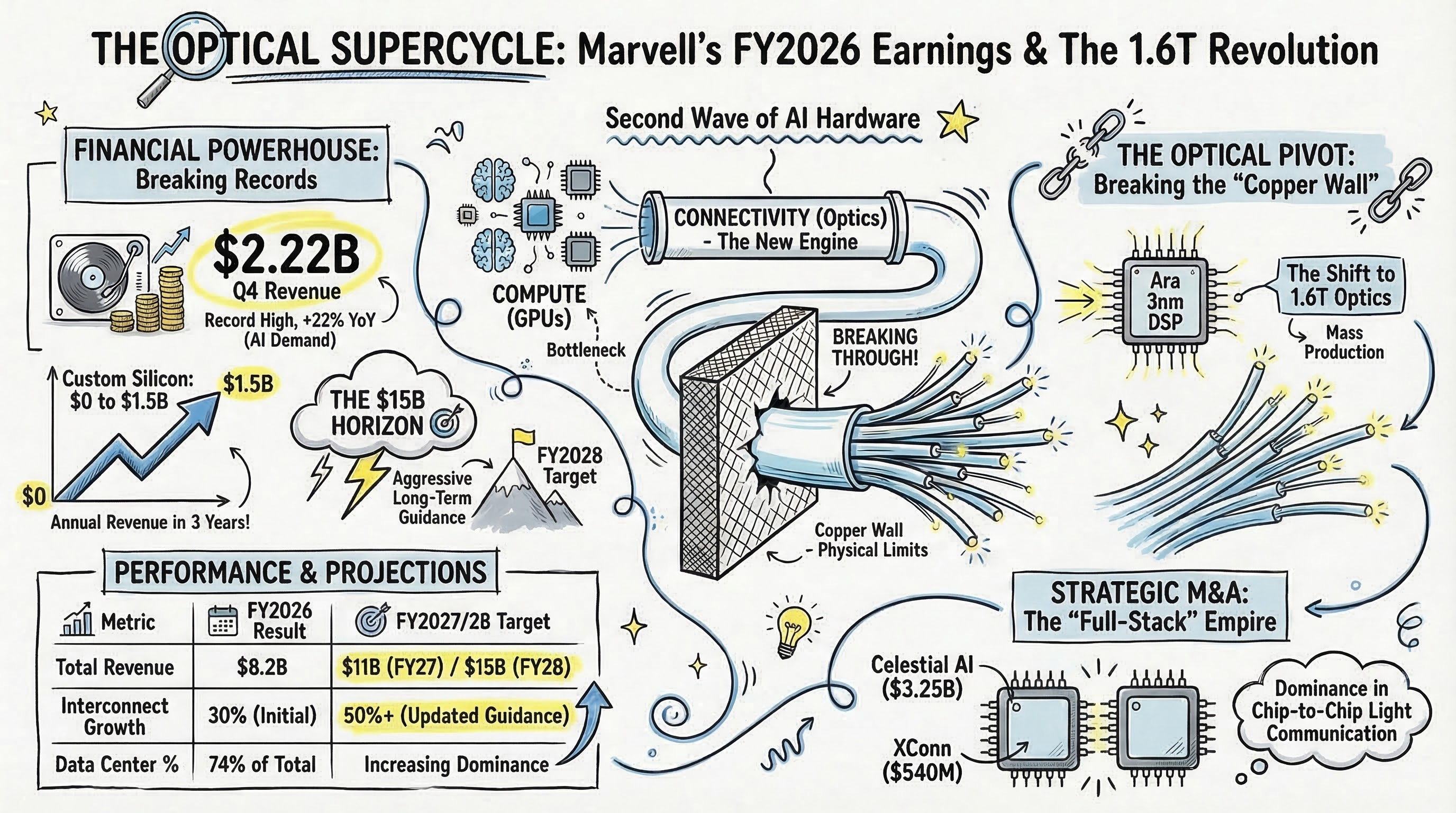
1. The Numbers
Marvell Q4 revenue: $2.219 billion (+22% YoY, all-time record) Full-year revenue: $8.195 billion (+42% YoY) Excluding the divested automotive Ethernet business, organic growth was +45% Data center segment: 74% of total revenue, $1.65 billion in Q4 — an all-time high
So far, so good. But the really striking number is this:
Custom silicon revenue surged from $0 just a few years ago to $1.5 billion in FY2026. Volume production started in FY2025, and revenue doubled year-over-year in FY2026.
What this means is that Marvell is no longer just a merchant chip vendor — it’s been elevated to a strategic co-design partner for hyperscaler core compute architectures like AWS’s Trainium2 and Google’s Axion CPU. From $0 to $1.5B in just 2–3 years. Let that sink in.
And management’s guidance is aggressive:
FY2027: Revenue approaching $11 billion (+30%+ YoY)
FY2028: Revenue $15 billion, Non-GAAP EPS $5+ (longer-term target from prior investor communications)
This $11B number has been revised upward repeatedly. At a JPMorgan investor call in September 2025 it was ~$9.5B, then raised to ~$10B at the December earnings call, and now bumped up another ~$1B. Management attributes this to continued upward revisions in cloud CapEx forecasts and accelerating bookings. And this outlook doesn’t include any revenue contribution from the recently acquired Celestial AI or XConn. This is purely organic growth.
Let me walk through why this isn’t just talk. But first, one critical framing — where exactly is ‘optics’ in these earnings?
① The violent upward revision of interconnect (= optics) guidance:
30% → 50%+: This was the single most emphasized point in the earnings call. CEO Matt Murphy stated: “We expect our interconnect business to grow more than 50% year over year, well above our prior expectation of 30% growth.” The vast majority of Marvell’s interconnect revenue comes from pure optical products: 800G/1.6T PAM4 optical DSPs (Ara), coherent DSPs (Electra), and COLORZ 1600 DCI modules. When the company’s overall guidance is +30% but the optical segment alone is +50%+, that’s financial proof that optics is hard-carrying the entire company’s results. This interconnect growth revision is the primary engine that lifted the overall FY2027 forecast from $10B to $11B.
② 1.6T optical DSP ‘Ara’ enters volume production ramp:
Management stated that “1.6T solutions entered production in the second half of fiscal 2026” and that they “expect 1.6T revenue to ramp very rapidly in fiscal 2027.” Q4 data center revenue of $1.65B (all-time record) was explicitly attributed to “sequential growth across optical interconnects, custom silicon, switching, and storage.” The 1.6T generational shift that the market has been waiting for has officially started hitting the P&L — and it explodes in FY2027.
③ Custom silicon explosion = leading indicator of optical demand explosion (Attach Rate):
Custom silicon revenue surging from $0 to $1.5B means hyperscalers are deploying their own AI chips (AWS Trainium, Google Axion, etc.) at a furious pace. But scaling these hundreds of thousands of compute chips into massive clusters runs into clear physical limits with copper alone. Every custom chip deployed forces the attachment of high-speed optical transceiver modules to handle external high-speed data transmission. The custom silicon revenue explosion is a perfect leading indicator of the optical pipeline demand explosion that follows. Management guided custom business to “at least double year-over-year” in FY2028, meaning optical interconnect attach demand scales proportionally.
In short, Marvell’s earnings aren’t just a “semiconductor company did well” story. They’re a financial confirmation that optical interconnects have become the dominant growth engine of the AI data center. And the fact that design wins — the number of customer commitments to use Marvell’s chips in their next-generation products — hit an all-time record means the fuel for this engine will keep flowing for years.
2026: The Inference Inflection
Let’s set the big picture first. Entering 2026, over 55% of hyperscaler AI-optimized infrastructure spending has shifted from foundation model training to real-time inference — an inflection point.
GPU performance has been scaling exponentially, beyond Moore’s Law. But the problem is that the data movement pipeline — the network interconnect — hasn’t kept pace with that compute power. The result: inside massively capitalized AI factories, a significant portion of GPUs sit idle due to inefficient job scheduling and data wait times. Industry reports suggest that GPU utilization in large-scale clusters commonly stays in the 60–70% range.
When H100 GPU clusters sit idle while consuming power, 700W chips eat electricity doing nothing — driving up carbon emissions and OPEX. This isn’t just inefficiency; it’s a structural problem eating into the ROI of multi-billion-dollar investments.
For CTOs operating AI infrastructure, the ultimate KPI isn’t GPU clock speed. It’s Job Completion Time (JCT). If you can’t reduce JCT, billions of dollars in cluster investment go to waste. That’s why hyperscalers are racing to deploy 1.6T (Terabit-per-second) optical networking infrastructure across intra-rack, rack-to-rack, and inter-datacenter links.
Marvell’s earnings are the clearest evidence yet that capital is rotating en masse toward companies that control the blood vessels connecting Nvidia’s compute.
Key takeaway: The primary constraint on AI infrastructure has shifted from compute to connectivity. The 1.6T optical interconnect market is exploding as operators race to minimize JCT, and Marvell’s FY2028 $15B guidance is the opening salvo of this structural supercycle.
2. Deep Tech: The Limits of Copper and the Inevitability of Optics
2.1 The Copper Wall
As AI clusters have expanded from 10,000 GPUs to 100,000 and now toward 1 million, the copper-based interconnect technologies that once formed the backbone of data center networking have hit a physics wall — the Copper Wall.
Traditionally, short-reach server-to-switch links used passive copper twinax cables (DACs). Cheap, reliable, no issues. But as bandwidth doubles from 400G to 800G to 1.6T, serious problems emerge:
Skin Effect: At high frequencies, current concentrates on the conductor’s surface, spiking resistance
Insertion Loss: At 200Gbps per lane (200G/lane), passive copper cable reach drops to 2–3 meters — barely enough for intra-rack top-to-bottom connections
“Just use thicker cables?” In a 1.6T high-density switch environment, hundreds of fat cables completely block rack airflow. Thermal collapse. Cooling fails.
Active Electrical Cables (AECs) with retimer chips can extend reach to 5–7 meters, but their power draw exceeds per-rack power constraints when thousands of links are deployed.
The bottom line: in scale-out architectures where 100,000+ GPUs are distributed across tens of meters and must constantly exchange massive data for All-reduce synchronization, optical interconnects are the only solution that simultaneously overcomes bandwidth, reach, and power density limits.
Fiber-optic links can transmit data loss-free across tens of meters to kilometers. Legacy optical modules had their own issues — high power consumption in E/O conversion and failure rates up to 100x that of copper — but solving these problems is exactly what’s driving innovation across the entire value chain. And Marvell sits at the center.
2.2 PAM4 DSP: The Brain of Optical Communications
The critical brain that overcomes these physical limits and ensures optical signal integrity is the Digital Signal Processor (DSP).
In high-speed optical communications, data is encoded not as simple 0s and 1s (NRZ) but using PAM4 (Pulse Amplitude Modulation 4-level) — transmitting 2 bits per symbol across 4 amplitude levels. This naturally introduces signal distortion, chromatic dispersion, and noise. Correcting these mathematically and performing Forward Error Correction (FEC) is the DSP’s core job.
Marvell is the undisputed leader in PAM4 DSP.
Key points from the earnings release:
Robust hyperscaler demand for 800G PAM4 DSPs continues
Next-gen 1.6T solutions entered volume production in Q4
Marvell’s 1.6T optical DSP ‘Ara’: industry-first 3nm process, 200G/lane interfaces
20%+ power reduction per bit vs. prior 5nm-based 800G generation (per Marvell’s official announcement)
Power efficiency matters enormously because optical modules are consuming an ever-larger share of total data center power budgets. Power per bit has become the most critical engineering metric. Marvell’s 3nm Ara platform, with its advanced node and optimized FEC algorithms, has mitigated pluggable optics’ biggest weakness — power consumption — and successfully ushered in the 1.6T era.
LightCounting analyst Bob Wheeler projects PAM4 DSP unit shipments will more than triple from 2024 to 2029, reaching approximately 127 million units annually, stating they will “remain the primary optical technology for connecting assets inside data centers for the foreseeable future”.
Beyond 2H 2026, the next speed transition to 3.2T is on the horizon via 200G/lane → 400G/lane evolution. Ara currently supports 200G/lane, and industry roadmaps (Ethernet Technology Consortium, IEEE 802.3 standardization) suggest 400G/lane-based 3.2T modules will begin sampling in 2027–2028.
2.3 Form Factor Evolution: Pluggable → CPO → Optical I/O
This is personally the most fascinating part. As bandwidth surges past 1.6T toward 3.2T and 6.4T, the physical form of optical communications is undergoing a fundamental architectural shift.
💡 [Form Factor Evolution]
Pluggable (OSFP/QSFP-DD)→LPO (DSP removed)→CPO (ASIC + optics on same substrate)→Optical I/O (intra-chip photonics)Power efficiency: ~15 pJ/bit → ~10 pJ/bit → ~5-7 pJ/bit → ~few pJ/bit Reach: hundreds of meters–2km → hundreds of meters → meters–tens of meters → chip-to-chip direct
Pluggable Optics — Today’s data center workhorse. OSFP or QSFP-DD modules plug into switch front panels for easy serviceability. But the long electrical trace from switch ASIC to front-panel module wastes significant power compensating for signal attenuation.
LPO (Linear-drive Pluggable Optics) — A transitional approach that removes the power-hungry DSP chip inside the module, using only analog linear drivers. Gets power down to ~10 pJ/bit but sacrifices signal correction capability, making system-wide BER control difficult.
CPO (Co-Packaged Optics) — The game changer. Places the optical engine (silicon photonics) and switch ASIC on the same package substrate, shortening copper traces to millimeters. This eliminates signal loss at the source, dramatically improving efficiency to ~5–7 pJ/bit (Broadcom’s benchmark). Initial concerns about thermal management and external laser sourcing are being resolved as CPO becomes essential for high-end AI systems.
Optical I/O / Photonic Fabric — The ultimate evolution. Beyond switches, this stage performs GPU-to-memory (HBM) communication using light. This is the core technology domain of Celestial AI, which Marvell acquired. By bringing optical communication down to the transistor level inside silicon, it breaks through the Memory Wall.
Why does this matter? Industry estimates suggest Nvidia’s NVLink consumes roughly 62.5 pJ/bit, while Celestial AI’s Photonic Fabric operates at just a few pJ/bit with ultra-low latency — a potential efficiency improvement of several times to 10x. Celestial AI’s thermal stability is a key differentiator, enabling reliable operation in extreme heat environments created by multi-kilowatt XPUs, allowing vertical 3D packaging directly on top of XPUs rather than edge connections — freeing up precious die-edge real estate for more HBM.
2.4 Marvell’s Architecture Strategy: Scale-Out, Scale-Across, Scale-Up
Marvell’s recent M&A and product roadmap reveal a clear strategic intent to evolve beyond a component supplier into an end-to-end architect controlling all data flows inside AI data centers.
Scale-out — Rack-to-rack traffic. Marvell deploys its Ara 1.6T PAM4 DSP and Ethernet switch IP here. The earnings call revealed interconnect business expected to grow 50%+ YoY in FY2027, sharply above the prior 30% guidance.
Scale-across — Data center-to-data center. Power and space constraints prevent housing hundreds of thousands of GPUs in a single building, creating explosive demand for connecting geographically distributed data centers as a single virtual cluster. Marvell targets this DCI market with its industry-first 2nm 1.6T ZR/ZR+ coherent DSP ‘Electra’ and ‘COLORZ 1600’ module, featuring hardware MACsec encryption integrated on-chip for secure campus-to-campus transmission.
Scale-up: Chip-to-chip direct communication. This is the highlight. Marvell acquired Celestial AI ($3.25B) for its optical ‘Photonic Fabric’ technology.
But here’s what’s even more interesting: XConn Technologies ($540M). If optics is the future, why did Marvell buy a copper-based PCIe/CXL switch company? It’s not just about chips. It’s about seizing switching dominance over UALink (Ultra Accelerator Link) — the open standard that the anti-Nvidia coalition is building to counter Nvidia’s proprietary NVLink ecosystem.
Short-range (intra-rack) gets bound by XConn’s UALink copper switches; long-range (rack-to-rack, chip-to-chip) gets connected by Celestial AI’s optics. A complete anti-Nvidia ‘hybrid interconnect empire.’ As TechArena put it, “they didn’t buy a science experiment; they bought the plumbing for GPT-6”.
Celestial AI acquisition: $3.25B (up to $5.5B with revenue milestones). AWS VP David Brown commented that this will “help further accelerate optical scale-up innovation for next-generation AI deployments”. Acquisition closed February 2, 2026.
XConn Technologies acquisition: $540M. PCIe Gen 6 and CXL 3.1 switching for near-range memory pooling. Already engaged with 20+ customers; PCIe 5 / CXL 2.0 switches in production, PCIe 6 / CXL 3.1 sampling. Revenue contribution starts FY2027 Q3, targeting $100M in FY2028.
Key takeaway: As copper hits its physical wall, data centers are being forced through an architecture transition: 1.6T pluggable → CPO → optical I/O. Marvell’s acquisitions of Celestial AI ($3.25B) and XConn ($540M) extend its reach from scale-out (rack-to-rack) into scale-up (chip-to-chip), completing full-stack dominance of the AI data center interconnect market.
3. Global Optical Value Chain Mapping & Competitive Analysis
The optical interconnect ecosystem is fragmented into highly specialized layers. As the industry enters the 1.6T commercialization era, fierce technology and market share battles are underway at every tier.
