
SpaceX Started Renting Out Compute. The Rig Demand Is Now Written Into the Contract.
$SPCX $NVDA | Colossus Offtake: Scale-Out Optics and Field Validation, One Layer Down


The copper in NVL72 did not kill optical demand. The market was looking inside the rack. The money is outside it. When NVIDIA wired its 72 GPUs together over an NVLink copper spine, a bear case followed: maybe optical content shrinks. That is the read SemiAnalysis called the “optical boogeyman.” But it treats scale-up and scale-out as the same network, and that is only half the picture. The moment Reflection AI signed a compute deal with SpaceX on June 22, 2026, for $150M a month and up to roughly $6.3B through 2029 [1][2][3], this stopped being GPU-rental news and became scale-out optics and field-validation news. SpaceX, which went public on June 12 ($SPCX), is shifting Colossus into a business that rents capacity to outside AI labs [4][5][6], and Anthropic (about $45B) and Google (about $30B) are already tenants on the same infrastructure [4]. Tickers in focus: $SPCX, $NVDA.
Reflection agreed to pay $150 million a month to rent compute
Start with the deal.
Reflection AI will pay SpaceX $150M every month from July 1, 2026, for access to GB300 chips. Run to the end of 2029, that is about $6.3B [1][2]. After the first three months, either side can terminate on 90 days notice [1][2]. Reflection is an open-weight model startup founded by former DeepMind researchers, Nvidia put in $800M, and its recent valuation is $25B [1].
This is not even the first deal. Tenants are lining up for the same Colossus.
Anthropic: deal value about $45B, through mid-2029 [4].
Google: deal value about $30B, through mid-2029 [4]
Cursor: being acquired by SpaceX (an acquisition, not a lease) [3][4]
Reflection: $150M a month, through end of 2029 [1][2]
Colossus, originally built to train Grok, has turned into a business that rents chips to outside AI labs [4]. The compute appetite of the open-weight camp is also adding demand to this rental model [5]. And on June 12, SpaceX went public and within days became one of the most valuable listed companies by market cap [6]. That said, $SPCX spiked right after listing and has since pulled back amid a roughly $20B bond offering and valuation concerns [6].
What matters here is not who the tenants are. It is that GPU utilization has started carrying a monthly price tag. Once rent is attached, the physical infrastructure underneath is no longer “capex that might get used someday” but “gear that has to hit a utilization target.” Compute is moving from an asset you buy to an asset you rent.
Compute is no longer gear you buy once. It has become an asset metered as monthly rent.
The Numbers on the Contract Split Into Copper and Light
For anyone who has not read the prior piece, in one line: in an AI buildout, the layer everyone passes through in a supplier-neutral way is optical modules, wafer/test, and deployment validation. This deal signals that demand at that layer is no longer just a vague capex inference. (Background is in Compute Is the New Oil. So Who Builds the Drilling Rigs?.)
Compute Is the New Oil. So Who Builds the Drilling Rigs?

In the same month, CME and ICE both announced compute futures tied to GPU rental rate indices, and compute began turning into a cash-settled exchange commodity.[1][2] Put SpaceX’s Cursor acquisition, the Oracle-OpenAI $300B/4.5GW deal, and Microsoft-OpenAI’s end of exclusivity in one frame, and the unit the market prices is shifting from chip ASP to contracted compute.[3][4][5] The thesis here is simple. Contracting GW eventually translates into wafer starts one layer down, and no matter who wins at the chip and compute layer, the supplier-agnostic layer everyone passes through is deposition, etch, bonding, probe, burn-in, ATE, and metrology. If compute is oil, part of the money is made not at the oilfield but in the rigs that drill it and the tools that inspect it.
The difference looks small but matters for investors. When a buildout sits on “demand will show up someday,” that is speculative capex. But when contracts with named amounts and end dates sit on top, like Anthropic, Google, and Reflection, the hardware demand underneath gains visibility [4]. With a 90-day termination clause, you cannot say it is “locked in” [1]. What changes is the question, from “will demand come” to “how much utilization is already contracted.”
So one layer down, what physical demand does that rent roll become? Hundreds of thousands of GPUs is a number on paper, but the moment it draws a path inside the rack, it splits into copper and light.
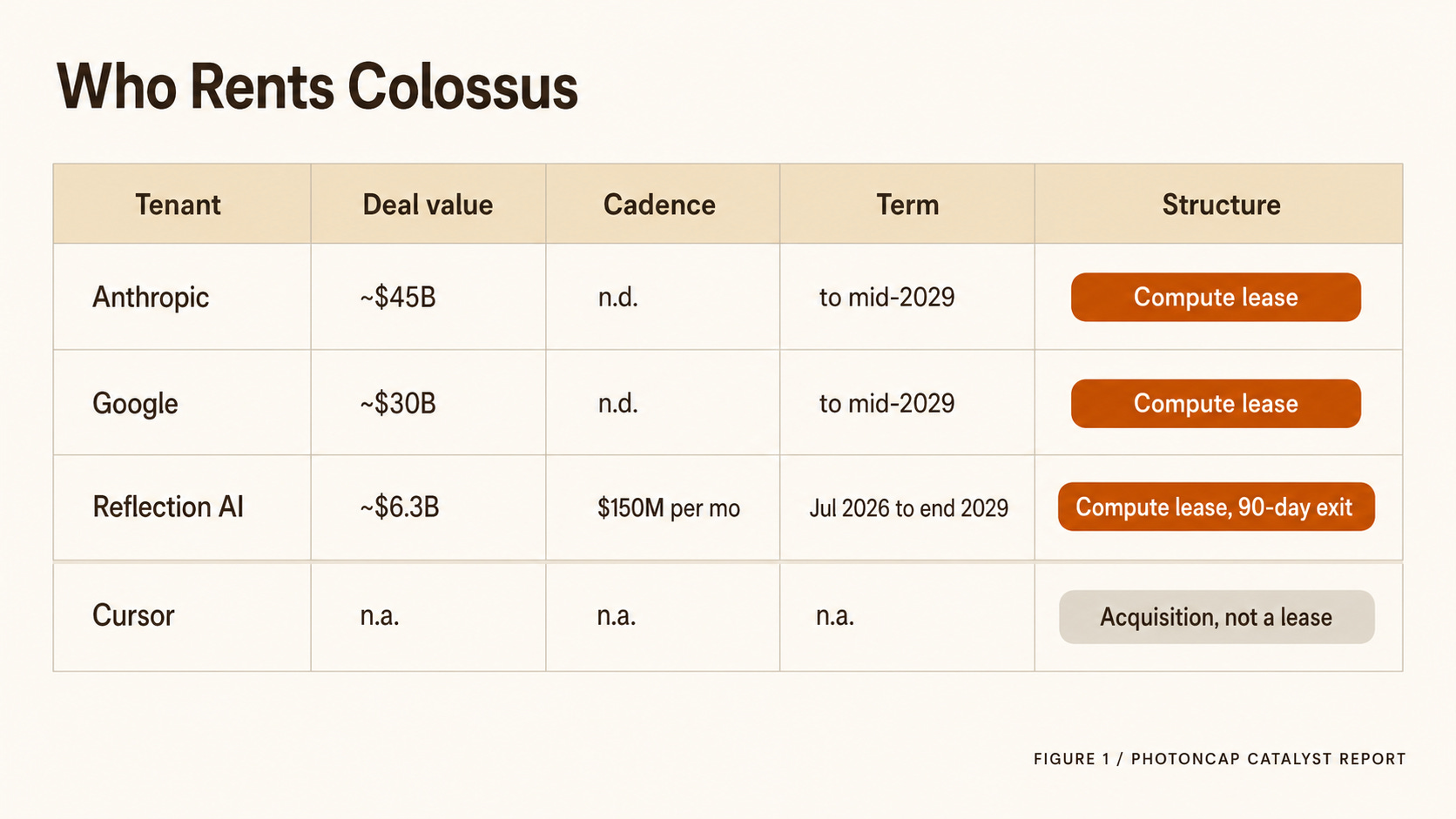
Figure 1. Colossus tenants by compute deal size and term.
Where the market misread it is the NVL72 copper spine
The problem is treating scale-up and scale-out as the same network.
A GB300 NVL72 rack holds 72 Blackwell Ultra GPUs and 36 Grace CPUs [7][8]. Power runs roughly from the 120kW range to the mid 150s kW depending on configuration and workload, and by Lenovo’s document it is 135kW TDP and up to 155kW peak [8][9]. This rack uses two kinds of network.
First, scale-up. Inside the rack, 72 GPUs are bound into one NVLink domain (1.8TB/s bidirectional) [7]. This is copper. Nvidia made it copper on purpose. Running the same links over optical transceivers would add about 20kW just for transceivers and retimers, so Nvidia wired the NVLink spine directly in copper to spend that power on compute instead [10]. That copper scale-up choice is what drove the “NVL72 kills optics” read, the one SemiAnalysis named the “optical boogeyman” and rebutted [10]. (Note that the recent optical-stock selloff is more about profit-taking on rich multiples than about this read. They are different things.)
Second, scale-out. The compute (East/West) fabric that links rack to rack. This is different. By NVIDIA’s reference architecture, an NVL72 rack (18 trays) puts a ConnectX-8 board on each tray to build the East/West fabric, and the per-tray aggregate bandwidth of that fabric is 3200 Gb/s [7]. Across the full rack, that is 72 scale-out connections at 800G class, matching the 72 GPUs. At the order-of-magnitude level, the key is one 800G-class scale-out connection per GPU [7][8][9]. And this East/West interconnect makes broad use of pluggable optical transceivers and detachable fiber [7]. Wiring the inside of the rack with copper does not reduce the optical ports leaving the rack.
So reading NVL72 as “less optical” is only half the picture. Scale-up did go copper, but optical intensity (scale-out ports per GPU) does not drop [10]. And as a cluster grows, spine sits above leaf and super-spine above that [7], so optical port demand actually rises with GPU count.
The copper in NVL72 is a scale-up story, not a scale-out story. The bigger the cluster, the more scale-out optical demand scales with GPU count.
Converting GPU count into optical ports and field-validation events
Now drop Colossus 2 scale into the physical layer. First, the uncertainty in the scale numbers. Colossus 2 bought its site last March and came online this January. Planned capacity has been reported at 2GW, roughly 555,000 GPUs, and about $18B, but these are not company-confirmed figures (trade press reporting, not confirmed by the company). In fact, against Musk’s claim of 1GW, January satellite imagery showed cooling for only about 350MW, and May reporting had 19 gas turbines being deployed [6]. So there is a large gap between plan and observation. The conversion below applies GB300 NVL72 reference-design ratios as an order-of-magnitude illustration, and Colossus 2’s actual GPU generation mix and topology have not been confirmed by the company (author estimate).
The ratio is simple. At the scale-out leaf level, it is one 800G port per GPU [7][8]. At a scale of hundreds of thousands of GPUs, that is hundreds of thousands of 800G ports at the leaf level alone (author estimate). Each optical link carries a transceiver at both ends, and once spine tiers sit above leaf, total transceiver count becomes several times the GPU count [7] (author estimate). Strip out the short runs handled by DAC/AEC and the real optical transceiver count comes in below that, but the order-of-magnitude feel is “hundreds of thousands of GPUs equals hundreds of thousands of scale-out ports, and once upper network tiers are included, a much larger number of optical transceiver endpoints.”
What the contract becomes at the physical layer:
1 GPU → 1 scale-out 800G-class connection
1 NVL72 rack → 72 GPUs → 72 scale-out connections
Hundreds of thousands of GPUs → hundreds of thousands of scale-out ports (at leaf)
Every optical endpoint → insertion-loss / return-loss / OTDR / BER validation
And each optical connection creates at least one field-validation event. (This is a different layer from semiconductor ATE test insertion. Package-level test insertions grow separately, and what we mean here is fiber field validation.) Field guides show GB300 deployments bringing in pre-terminated 144-fiber trunks and validating every connector with insertion-loss, return-loss, and OTDR [11]. More important, even transceivers that pass commissioning see BER drift as temperature rises, so a module that was fine at 25C starts accumulating errors under sustained load at 35C [11]. This is not plug-once-and-done. It creates validation demand at install time and recurring in operation. Optical module and structured-cable lead times run to months, so they can sit on the critical path of a deployment schedule [11].
The logic from the prior piece meshes here. I argued that denser packaging makes package-level test insertions grow superlinearly because of known-good-die economics, and scale-out optics points the same way. More GPUs means more optical ports, and more optical ports means more field validation and BER monitoring.
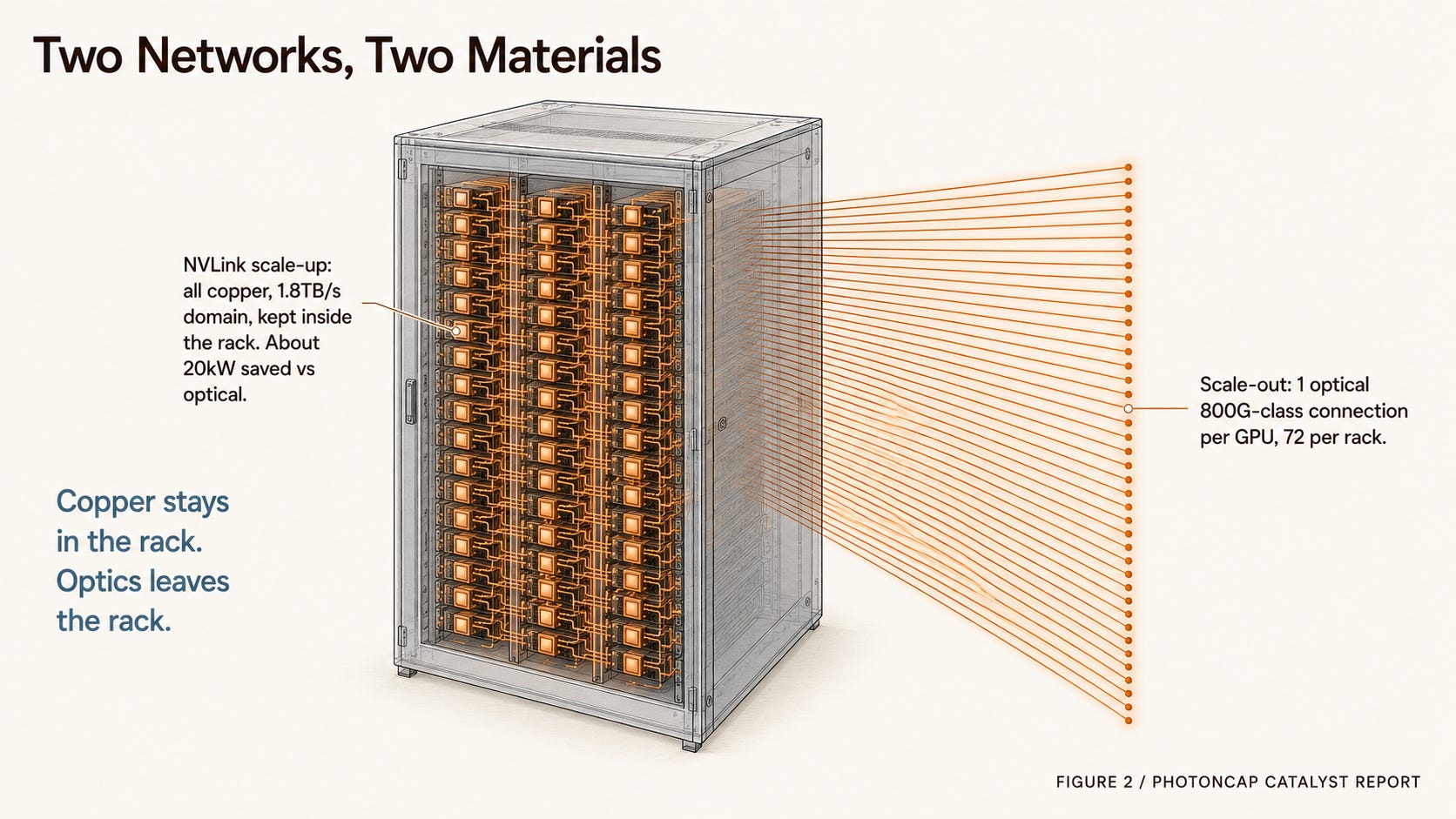
Figure 2. The two networks of GB300 NVL72: copper scale-up vs optical scale-out.
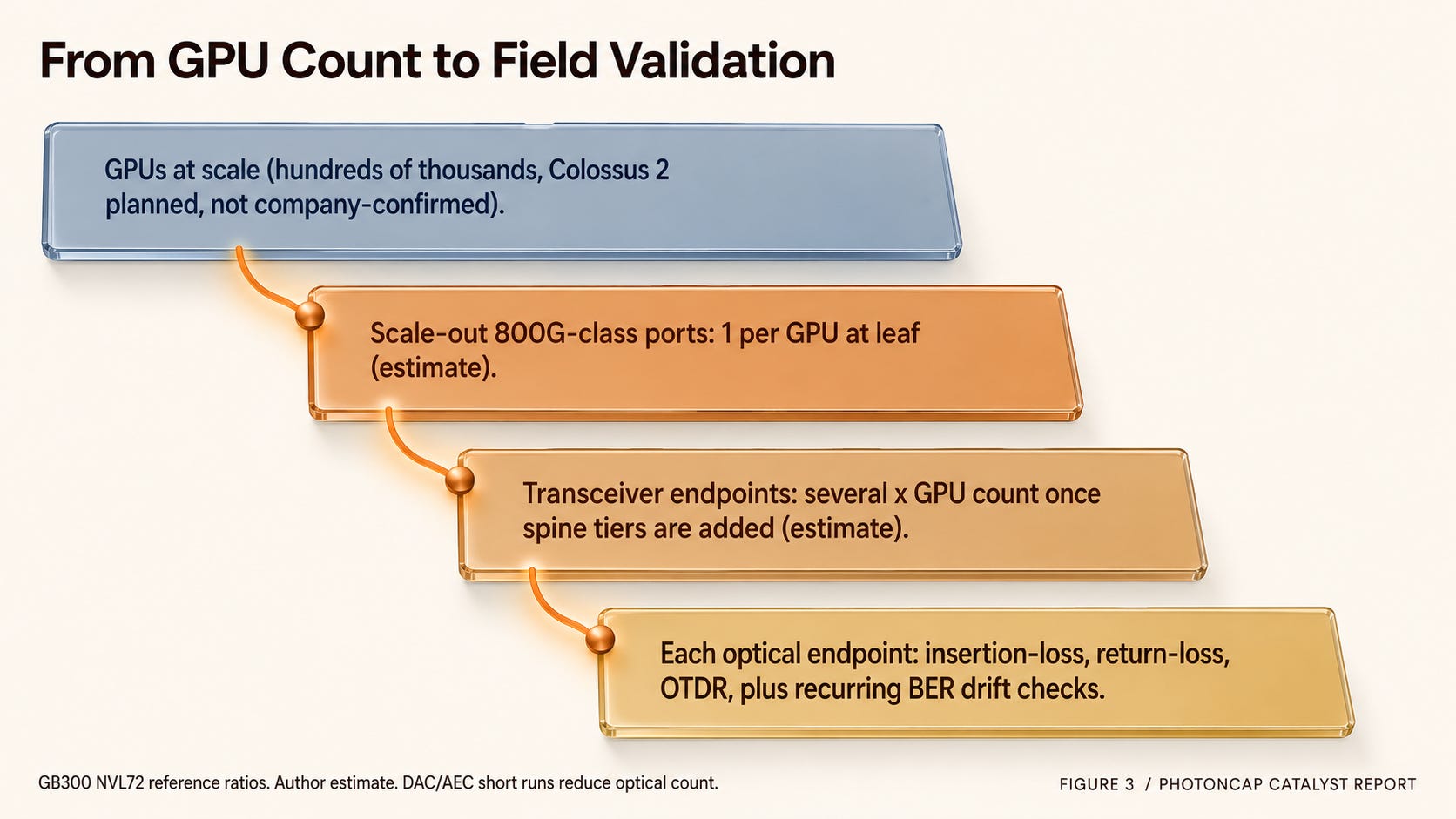
Figure 3. Translating GPU count into scale-out ports and field-validation events, an order-of-magnitude ladder.
How offtake contracts change equipment-layer beta
It is cleanest to split the demand into three layers. (This is a map of where demand lands, not a stock recommendation. The author holds no position in the names mentioned.)
Optical modules/transceivers: the direct beneficiary of scale-out ports moving from 800G to 1.6T. Representative names include Coherent ($COHR) and Lumentum ($LITE).
Silicon photonics/packaging: the layer that benefits when value shifts from modules to on-package via CPO/LPO.
Optical/network test: field validation, BER, and production test. Representative names include Viavi ($VIAV) and Keysight ($KEYS).
One more structural point. A module vendor’s beta tracks closer to the port count, while a test vendor’s beta tracks closer to port count times operational complexity. So as the network moves from 800G to 1.6T, the leverage on validation difficulty can grow faster than raw unit counts. The test layer can be a more convex layer, not just trailing demand.
The key is that the character of demand changes. Before, you inferred “optical demand should follow” from hyperscaler capex guidance. Now the contract values are stated, like Anthropic about $45B, Google about $30B, and Reflection about $6.3B [4]. When a tenant runs that compute, GPUs run, and for GPUs to run, scale-out optics has to be in place, and that optics goes through validation.
Of course the 90-day termination clause is the biggest crack [1][2]. The full contract value is not guaranteed revenue. But one thing is clear. The GPU infrastructure already installed stays in place even if a tenant leaves, and taking the next tenant needs the same scale-out optics and validation. Optical and test demand is tied to the infrastructure itself, not to any single tenant.
The optical module market is not small either. 400/800G datacom optics is estimated to grow from about $9B in 2024 to about $16B in 2026, and AI-cluster optics is estimated to already exceed $4B a year [12]. Weigh one Colossus 2 buildout against that market and you can see how much a single offtake contract carries.
Tenants can change, but the scale-out optics and field validation needed to take the next tenant stay fixed to the infrastructure. The beta shifts from tenant risk to infrastructure utilization risk.
Scenarios and Monitoring
Base Case. Colossus 2 buildout proceeds as planned and tenant utilization holds. Scale-out optics and validation demand land in proportion to GPU count, and the equipment layer’s revenue visibility firms up one notch, from capex inference to contract-based.
Alternative. If CPO (co-packaged optics) and LPO (linear pluggable optics) arrive faster than expected, the value of scale-out optics shifts partly from discrete module vendors toward switch/NIC silicon and silicon photonics [12]. Transceiver counts fall, but packaging and validation difficulty rises, so the center of gravity of the beta moves from modules to photonics packaging and test.
Downside. If the 90-day termination clause actually gets pulled [1], or if the Colossus 2 buildout slips on power and site constraints, contract-based visibility retreats back to inference. The gap between the 1GW claim and the roughly 350MW observation, plus filling power with gas turbines, puts a question mark over whether this buildout gets filled as planned [6]. In that case the offtake premium fades, and optical demand goes back to moving with the hyperscaler capex cycle.
Monitoring points. (1) Whether Colossus 2 discloses actual operating capacity and GPU generation mix [6], (2) additional tenant signings and termination disclosures, (3) the pace of the 800G to 1.6T transition, (4) timing of CPO/LPO adoption [12], (5) optical module lead times (currently on the order of months [11]), (6) how $SPCX share price and the bond offering affect the pace of capex execution [6].
PhotonCap’s View
Do not read this deal as an acquisition. What SpaceX is acquiring is Cursor, and Reflection is a tenant renting compute [4]. The distinction matters because an acquisition is a one-time event, while a lease is a recurring utilization signal.
I read this deal not as a stock call but as a change in the character of demand. The equipment and validation layer that everyone passes through in a supplier-neutral way now sits on a lease with a stated contract value, not on capex inference [4]. The simplest version is this. The moment compute becomes a rental asset, the scale-out optics and field validation that physically enable that rental asset stay with the infrastructure even as tenants change.
That said, the 90-day termination clause and the 1GW versus 350MW observation gap always put an asterisk on this picture [6]. The discipline of this piece is to not read contract values and planned capacity as guaranteed numbers.
GPU tenants can change. But the optical ports, the fiber plant, and the validation workflow laid down to take those tenants do not disappear. That is why this deal reads as optical supply-chain news, not GPU news.
References & Sources
[1] TechCrunch, “SpaceX inks compute deal with Reflection AI, an open source AI lab”, Jun 2026.
[2] Reuters, “AI startup Reflection signs computing power deal with SpaceX”, Jun 2026.
[3] The Wall Street Journal, “SpaceX Strikes $6 Billion Deal With AI Startup for Data-Center Space”, Jun 2026.
[4] CNBC, “SpaceX signs computing power deal with open-source AI startup Reflection worth up to $6.3 billion”, Jun 2026.
[5] Axios, “Open-source AI gets more compute from SpaceX”, Jun 2026.
[6] Data Center Dynamics, “SpaceX secures $6.3bn compute capacity deal from AI startup Reflection”, Jun 2026.
[7] NVIDIA, “Network Logical Architecture, NVL72 AI Factory Enterprise Reference Architecture”, 2026.
[8] Lenovo Press, “Lenovo NVIDIA GB300 NVL72 Rack Scale AI Product Guide”, 2026.
[9] Introl, “NVIDIA GB300 NVL72 Deployment Guide: Blackwell Ultra Specs and Engineering”, 2025.
[10] SemiAnalysis, “Nvidia’s Optical Boogeyman: NVL72, Infiniband Scale Out, 800G and 1.6T Ramp”, Mar 2024.
[11] Akash Borate, “Understanding how to bring up NVIDIA GB300 NVL72: From Facility to First Run”, May 2026.
[12] FPX Research, “Beyond Power: The Networking Bottleneck Starting to Take Shape”, Dec 2025.
Disclaimer: This article is an independent, engineering-driven technical analysis published by PhotonCap. All content is based on publicly available information and is intended for educational and informational purposes only. Nothing herein constitutes a recommendation to buy, sell, or hold any security. The author may hold positions in securities discussed and may transact at any time without notice. Readers should conduct their own due diligence before making any investment decisions.