The GPU era ran on TSMC. The inference era runs on multiple foundries: NVIDIA Rubin NVL8 and 14 stocks
NVDA, INTC, TSM, Samsung, Hynix, AVGO, AMD, TSLA, QCOM + 5 back-end OSAT stocks
Abstract
On December 24, 2025, NVIDIA and Groq announced a non-exclusive inference technology licensing agreement together with the move of key personnel into NVIDIA[1]. About three months later, in the GTC 2026 keynote (2026-03-16), NVIDIA unveiled a Rubin generation system design that no longer maps to “GPU = TSMC” alone[2][3]. Intel confirmed on the same day that its Xeon 6 had been adopted as the host CPU for the DGX Rubin NVL8 system[2], and the fact that the Groq lineage LP30 is manufactured at Samsung Foundry was disclosed by NVIDIA CEO Jensen Huang during the GTC keynote[4]. This article reads these announcements not as a single company event but as the visible point at which the training to inference to agentic workload bifurcation reshaped system design and the foundry supply chain into a multi-anchor structure. It maps the positions of the nine main tickers (NVDA, INTC, TSM, 005930, 000660, AVGO, AMD, TSLA, QCOM) and five back-end names exposed to the SK Hynix HBM cycle on top of primary sources. The free section covers the essential difference between training and inference workloads at the chip level, and the macro answer NVIDIA gave at GTC 2026. Which company’s chip went into which form across the Vera Rubin platform (NVL72 + Groq LPX + DGX Rubin NVL8 SKU), and how that decision creates differentiated exposures across the 14 stocks, is reserved for the paid section. Note that NVIDIA’s official marketing positions the Vera Rubin platform as configurable across multi-phase AI, and PhotonCap interprets the product positioning differential GTC 2026 made visible as a “training + large-rack track” vs “inference + agentic track” framing.
Contents
Intro
Tech background: training vs inference vs agentic workloads
NVIDIA’s macro answer at GTC 2026
Same cycle, different exposures
Vera Rubin platform multi-rack multi-anchor configuration + memory, packaging, host CPU bifurcation
Identifying the 9 main tickers + magnitude comparison
Four-group classification + differentiation table + per-company analysis
Scenarios + monitoring points + closing
References & Sources
1. Intro
There has been a meaningful change in NVIDIA’s system design over the past three months.
On December 24, 2025, NVIDIA and Groq announced a non-exclusive inference technology licensing agreement together with the move of Groq’s founder and key personnel into NVIDIA[1]. According to CNBC reporting, the deal size was around $20 billion[5]. Then, at the GTC 2026 keynote on March 16, 2026, NVIDIA unveiled a Rubin generation system design that no longer maps to “GPU = TSMC” alone[2][3]. On the same day, Intel confirmed via its official newsroom that its Xeon 6 had been adopted in the host CPU slot of the new system[2], and NVIDIA’s GTC 2026 blog announced the same system configuration at the same time[3].
The single sentence summary of why this matters is the following. PhotonCap reads GTC 2026 as the visible signal that NVIDIA’s AI system supply chain has begun shifting from a single-GPU-foundry centered structure to a multi-anchor structure where GPU, inference accelerator, and host CPU are differentiated. This is not a single company event but a structural result of the “training workload → inference workload → agentic workload” transition reshaping system design and the supply chain. That is why one platform announcement is moving the future positions of nine main tickers (NVDA, INTC, TSM, Samsung Electronics 005930, SK Hynix 000660, AVGO, AMD, TSLA, QCOM) and five back-end names exposed to the SK Hynix HBM cycle at the same time. The exact identity of the five back-end names and how each is exposed to the cycle is covered in Section 7 (4-group classification + per-company analysis) of the paid section.
The free section of this article is short. The two sections after this intro will work through (a) how training and inference are different jobs at the chip level, and (b) the macro answer NVIDIA put on the table at GTC 2026. That is the minimum technical context needed to understand the multi-anchor structure the Vera Rubin platform made visible. Which company’s chip went into which product form, how memory hierarchy and packaging and host CPU were differentiated, and the four-group mapping plus scenarios for the 14 stocks are all in the paid section.
Intro core: The Vera Rubin platform unveiled at GTC 2026 (NVL72 + Groq LPX + DGX Rubin NVL8 SKU) is the visible case where NVIDIA’s AI system has begun shifting from a single-GPU-foundry centered structure to a multi-anchor structure with GPU, inference accelerator, and host CPU differentiated across multiple rack forms. PhotonCap reads this as the structural result of the training → inference → agentic workload bifurcation, and this article maps how that bifurcation splits the positions of 14 stocks.
2. Tech background: training vs inference vs agentic workloads
What changes between training and inference at the chip level
Training a large language model and running inference on it look like the same job at the application level. Both involve neural networks, both run on GPUs, both consume GPU hours. But at the chip level, they are different jobs.
Training is a memory-capacity and chip-to-chip-bandwidth problem. To fit hundreds of billions of parameters onto memory and pipeline gradients across hundreds of GPUs, you need maximum memory capacity per GPU, maximum HBM bandwidth, and tightly integrated chip-to-chip interconnect. The NVIDIA Hopper and Blackwell generations were optimized exactly for this. GPU + HBM is the answer to the training question.
Inference is a different problem. Most of inference time is spent on decode (one-token-at-a-time generation), and decode is fundamentally a memory-bandwidth-bound operation. You are reading model weights from memory and producing one token. The bottleneck is not GPU compute, it is how fast you can pull the weights from memory. This is the part that GPU architectures cannot fully optimize, and it is the architectural gap that opens room for SRAM-first or memory-disaggregated chip designs.
Agentic workloads add another layer on top. An agent doing browser actions, querying multiple databases, calling APIs, planning multi-step tasks needs orchestration and control plane logic. This is naturally CPU work. Branch-heavy logic, scheduling, I/O management, this is what x86 and ARM CPUs were designed for over decades.
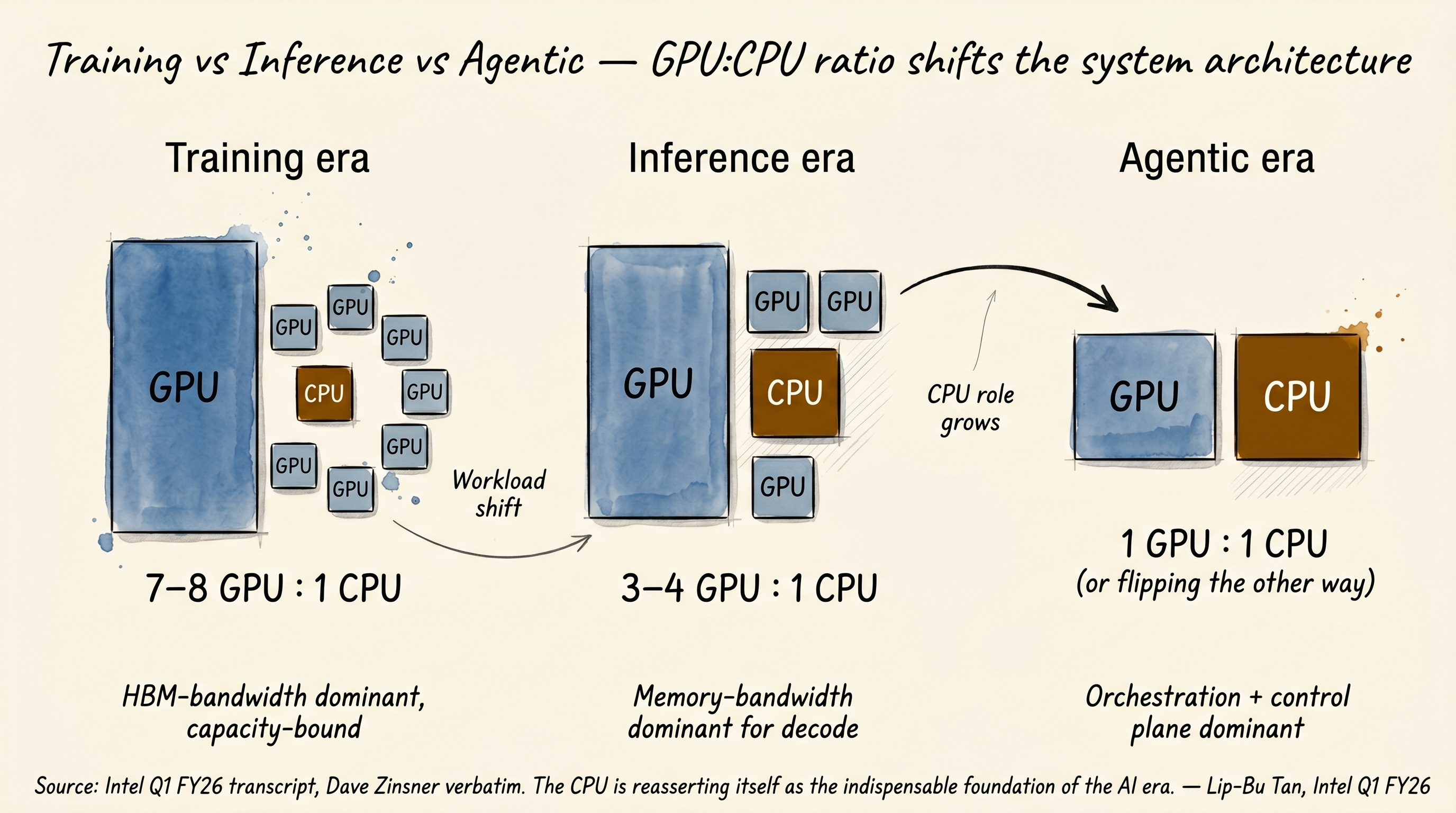
GPU:CPU ratio shifts the system architecture
The clearest way to see this shift is in GPU-to-CPU ratios. Intel CFO Dave Zinsner gave the verbatim numbers on the Intel Q1 26 earnings call. Quoted directly[6]:
“If you look at training solutions, you are running seven to eight GPUs to one CPU. As we look into inference, it is probably three to four to one. As you get into agentic and multi-agent, it is potentially even flipping the other direction a little bit.”
In the training era, eight GPUs share one CPU. The CPU is essentially a peripheral, a feeding mechanism for the GPU cluster. In the inference era, the ratio is three to four to one. The CPU role is roughly doubling. In the agentic era, the ratio is potentially inverting, more CPU than GPU. The CPU is no longer a peripheral. It is the orchestration layer.
Lip-Bu Tan opened the Q1 26 call with the same thesis as a verbatim narrative. Quoted directly[6]:
“For the last few years, the story around high performance computing was almost exclusively about GPU and other accelerators. In recent months, we have seen clear signs that the CPU is reasserting itself as the indispensable foundation of the AI era. The CPU now serves as the orchestration layer and critical control plane for the entire AI stack.”
Note Tan’s exact wording: “reasserting itself” and “the indispensable foundation of the AI era”. This is not a soft claim. It is a CEO declaring on an earnings call that CPU is back as a core asset of AI infrastructure. And it is backed by Q1 26 numbers. Intel revenue $13.6B (above $12.42B consensus), non-GAAP EPS $0.29 (vs $0.01 consensus), Data Center & AI segment revenue $5.05B (+22% YoY)[6]. This is hard data, not narrative.
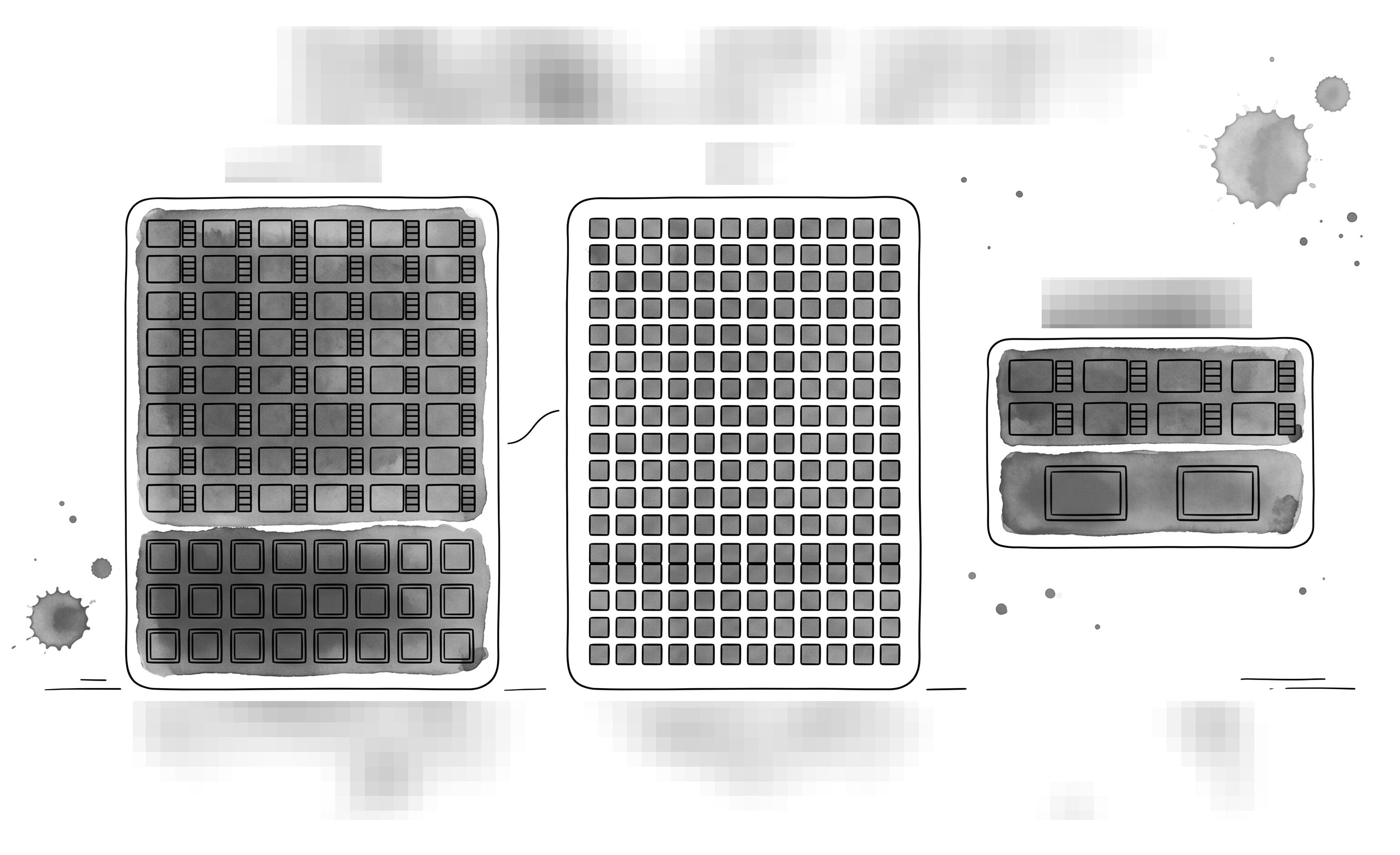
[Figure 1: training vs inference vs agentic workload, GPU:CPU ratio shifts and memory traffic structure]
This is where the divergence between training GPUs and inference accelerators starts. Training is decided by memory capacity and chip-to-chip interconnect, so GPU + HBM is the answer. But inference decode is bandwidth-bound by an order of magnitude, so different memory + different chip architectures are more efficient in some regions. What chip from which company belongs in this divergence and which memory hierarchy it uses is covered in Section 5 of the paid section.
Section 2 core: training and inference are different jobs at the chip level. Training is capacity- and chip-to-chip-bandwidth-bound, GPU + HBM is the answer. Inference decode is memory-bandwidth-bound, opening room for SRAM-first chip designs. Agentic adds an orchestration layer, which is CPU work. The GPU:CPU ratio confirmed by Zinsner verbatim is 7-8:1 for training, 3-4:1 for inference, and potentially inverting for agentic.
NVIDIA’s own stack already runs ahead of the curve
A point worth noting: Zinsner’s 7-8:1 training GPU:CPU ratio describes traditional x86 PCIe-based distributed deployments, while NVIDIA’s NVL72 (NVIDIA’s self-designed Vera ARM CPU + NVLink-C2C tightly integrated stack) already runs at 36 Vera CPUs + 72 Rubin GPUs = 2:1. The gap between the two ratios itself reveals the architectural distance between NVIDIA’s vertically integrated stack and general enterprise deployment, and as workloads move into inference + agentic, general deployment GPU:CPU ratios are likely to converge toward what NVIDIA already adopted. So Zinsner’s 7-8:1 → 3-4:1 → 1:1 or below scenario describes the evolution path for general deployments, while NVIDIA’s own stack has already baked that evolution into the design one step ahead.
3. NVIDIA’s macro answer at GTC 2026
Two systems unveiled at the same keynote
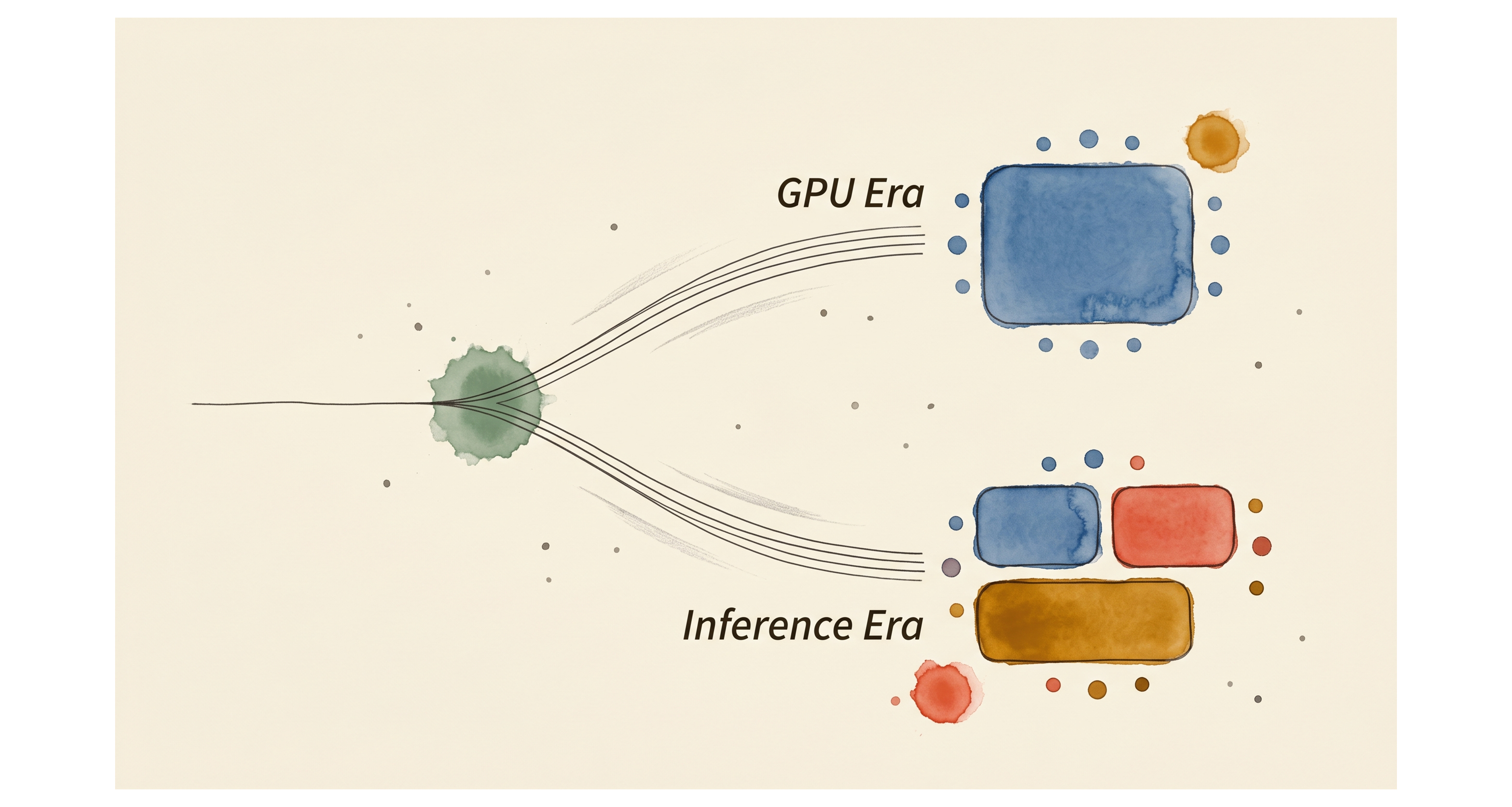
GTC 2026 (2026-03-16) saw NVIDIA announce not one but two systems at the same keynote. Vera Rubin NVL72 and DGX Rubin NVL8. Reading these two together gives the macro answer.
Vera Rubin NVL72 is the training + large-rack workload track. 72 Rubin GPUs in one rack. Host CPU is NVIDIA’s self-designed Vera (88 cores, ARM v9.2-A based). Foundry is TSMC single anchor. NVLink-C2C tightly integrates GPU and CPU on the same fabric. Tightly integrated, vertically aligned, NVIDIA’s complete stack.
DGX Rubin NVL8 takes a different design path. 8 Rubin GPUs in one rack, but inside that rack the host CPU is Intel Xeon 6, not NVIDIA Vera. Separately, the Vera Rubin platform also includes the Groq LPX rack, a separate inference rack form deployed alongside NVL72 that contains 256 Groq LP30 LPUs manufactured at Samsung Foundry SF4. So across the Vera Rubin platform (NVL72 + LPX + DGX Rubin NVL8 SKU) NVIDIA is simultaneously pulling in TSMC, Samsung Foundry, and Intel into its inference-era system stack across multiple rack forms, not bundling them into one rack.
These are the same Rubin generation chips at the GPU layer. NVL72 and DGX Rubin NVL8 share the Rubin GPU layer, while LPX adds a separate LPU-based inference rack paired with Vera Rubin NVL72. But everything else (host CPU, accelerator companion, foundry mix) is distributed across the platform. This is what GTC 2026 made visible. Workloads bifurcated, system designs bifurcated, supply chains bifurcated.
What this means as the macro answer
The single sentence compression of NVIDIA’s macro answer at GTC 2026 is the following. Across the Vera Rubin platform (NVL72 + Groq LPX + DGX Rubin NVL8 SKU), multi-anchor structure became visible simultaneously. The training + large-rack track (NVL72 itself) keeps NVIDIA’s own ARM CPU + GPU single foundry + NVLink-C2C tight integration. The inference + agentic track brings in external company chips and external foundries across two distinct rack forms: the LPX rack (Groq LP30 at Samsung Foundry SF4, paired with NVL72) and the DGX Rubin NVL8 SKU (Intel Xeon 6 as the x86 host CPU). The platform is built as a multi-anchor partnership across these forms, not packed inside any single rack. As Google Cloud showed at Cloud Next 2026 by announcing A5X bare metal instances based on NVIDIA Vera Rubin NVL72[7], NVL72 itself is not strictly training-only but a “training + large-rack workload centered” track, and NVIDIA’s own marketing positions both platforms as multi-phase configurable. This framing is PhotonCap’s interpretation of the product positioning differential NVIDIA intended, not a categorical “training=NVL72, inference=LPX/NVL8” binary. PhotonCap reads this as the essence of NVL as a system licensor position, the meaning of NVIDIA evolving from a pure GPU company into a system standard setter.
NVIDIA’s three capital allocations during the same period (2025-2026) make this platform strategy clearer. First, Groq licensing + personnel absorption (around $20B per CNBC reporting[5]). Second, $2B equity investment in Marvell + designation as NVLink Fusion partner (2026-03-31)[8]. Third, $5B equity investment in Intel (announced 2025-09-18, closed 2025-12-26)[9]. All three are platform-building capital allocations to bring other companies’ chips inside NVIDIA’s own system.
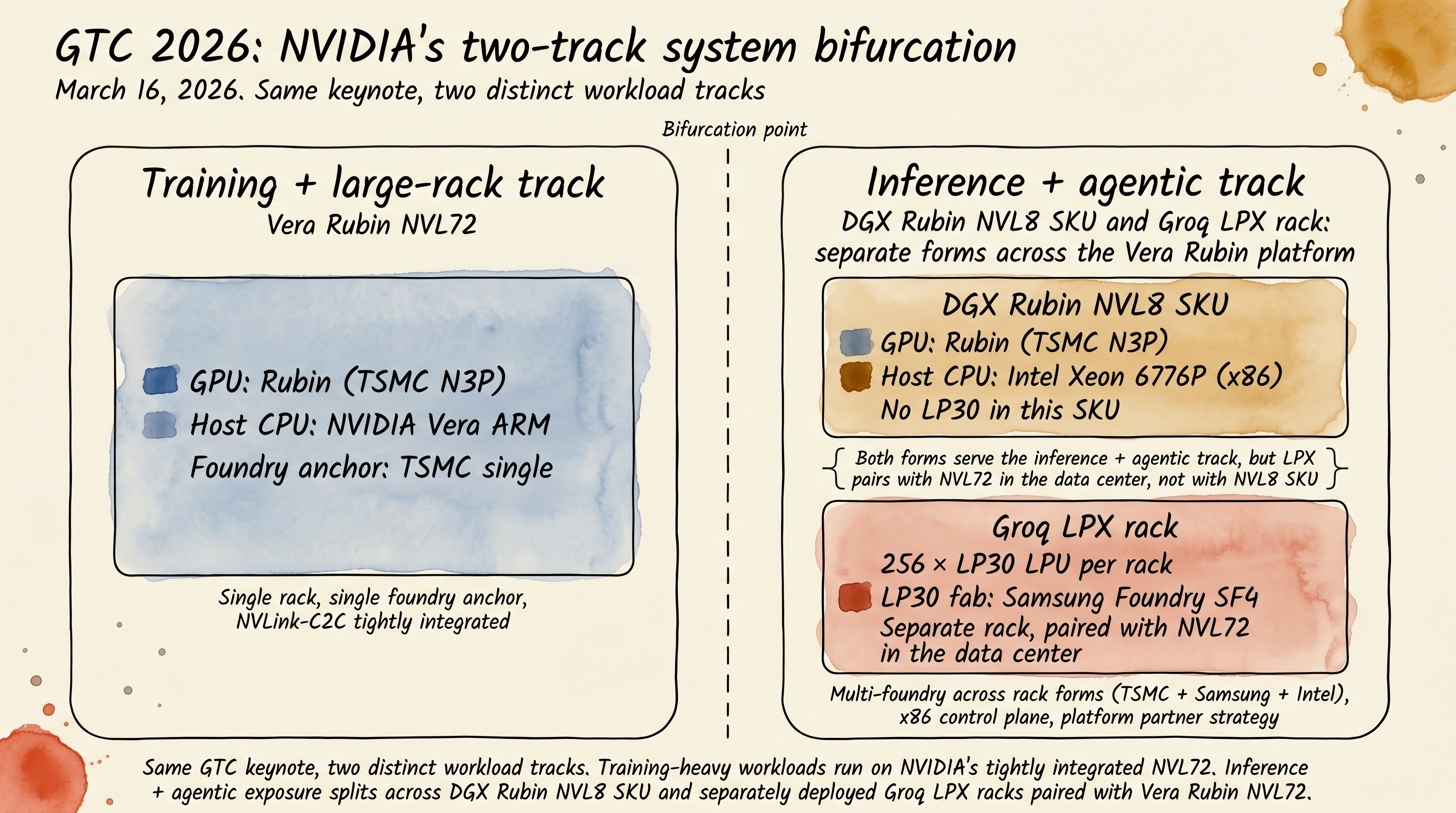
[Figure 2: GTC 2026 two-system simultaneous announcement showing training track vs inference + agentic track bifurcation diagram. The inference + agentic track is a track-level conceptual diagram showing both the DGX Rubin NVL8 SKU and the separate Groq LPX rack paired with NVL72. LP30 sits in the LPX rack, not in the NVL8 SKU itself.]
This is the macro answer GTC 2026 gave. And that is why which company’s chip ended up in which form across the Vera Rubin platform (NVL72 + LPX + NVL8 SKU) will determine the future positions of the nine main tickers + five back-end OSATs at the same time.
Section 3 core: GTC 2026 announced two systems at once. NVL72 keeps NVIDIA’s self-stack (Vera ARM CPU + TSMC single-anchor + NVLink-C2C tight integration) for the training + large-rack track. Across the inference + agentic track, DGX Rubin NVL8 brings in Intel Xeon 6 as the x86 host CPU, while the separate Groq LPX rack brings in Samsung Foundry LP30 alongside the Vera Rubin platform (TSMC + Samsung + Intel multi-anchor across rack forms). PhotonCap reads NVIDIA evolving into a system standard setter.
4. Same cycle, different exposures
You can see this far on public sources alone. The big picture, that the Vera Rubin platform made multi-anchor system configuration visible at GTC 2026, that the training → inference → agentic workload bifurcation is in the background, and that GTC 2026 began bifurcating the training track and the inference + agentic track via simultaneous two-system announcement, can be followed entirely by connecting three primary sources: NVIDIA’s GTC 2026 blog, the Intel Newsroom (2026-03-16), and the Intel Q1 26 earnings call.
The real difference starts here. The same “AI inference beneficiary” label hides very different positions: some stocks are already inside the system BoM, others only hold option value.
Among the 14 stocks covered in this article (9 main + 5 back-end), all are riding the same inference cycle, but in practice some are “stocks already integrated into system design”, some are “stocks with single-event exposure”, some are “stocks with only option value”, and some are “stocks on the separate inference ASIC track”. They are completely different. And there are two hidden cards in this cycle. One is the bifurcation that the two GTC 2026 systems created in the host CPU market (which company’s CPU went into which system). The other is the Terafab Intel 14A commitment that Elon Musk announced on the Tesla Q1 earnings call on April 22, 2026. These two cards are the core variables for asymmetric positioning over the next 12 months.